

Data is the golden key to the success of any business. However, it is vulnerable to disasters that disrupt business continuity. Be it a natural calamity, hardware or software failure, power outages, or any human error, safeguarding this data against all these disasters becomes our top priority. AWS offers disaster recovery solutions for both on-premise and on-cloud workloads.
Owing to the exponential growth of data over years, designing and deploying a skilfully architected backup solution becomes a challenging job. Here, we will discuss four standard Backup and DR strategies offered by AWS, arranged according to recovery times, at the same time higher cost and complexity. This provides a secure and stable way of business continuity.
Key factors for Disaster Planning
-
- Recovery Time Objective (RTO): This marks the time it takes for the business to restore to its defined service level after a disaster has occurred. The business decides on the maximum acceptable time gap between interruption and restoration of the services.
- Recovery Point Objective (RPO): This marks the acceptable amount of data loss in terms of time. The business decides the maximum acceptable amount of time since the last data recovery point.
Standard Approaches
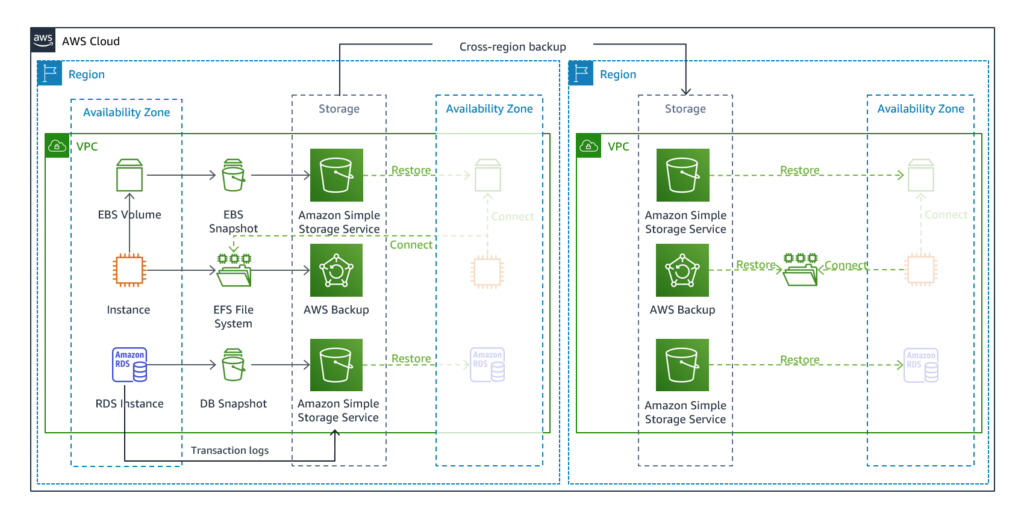
- Backup & Restore: As the name suggests, this methodology backs up data from your system to the AWS cloud and restores it from the defined Recovery Point Objective. It is recommended to backup Infrastructure, configuration, and application code also in the Recovery Region. To facilitate hustle-free redeployment, Infrastructure should always be deployed using Infrastructure as Code (IaC) using services like AWS Cloud Development Kit. AWS CodePipeline can be used for the automatic redeployment of configuration and application code. This technique costs the least because it does not host a live backup environment. On the other hand, it calls for the longest recovery time as it recovers the environment from scratch.
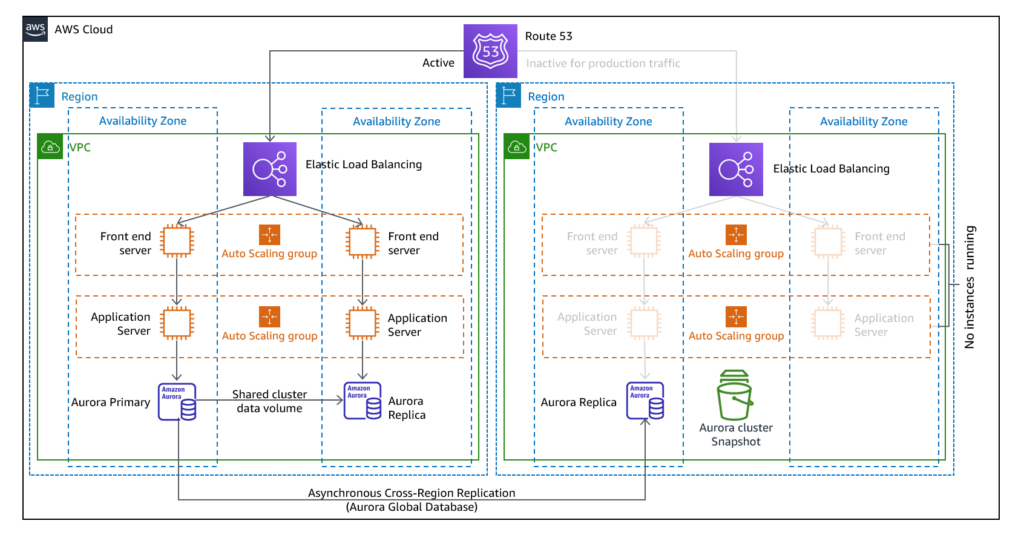
- Pilot Light: As per the name, this methodology uses a minimal backup environment. Data is replicated from one region to another and a copy of the core workload infrastructure is provisioned. Data backup and replication resources such as database and object storage are always ON. On the other hand, application servers are loaded with configurations and application code but are switched off. They are brought to use only during testing or when DR is invoked. Here a minimal version of the environment is always running on the cloud. This version hosts the critical functionalities of the application. This approach costs the least as most systems are down and are brought up only after a disaster.
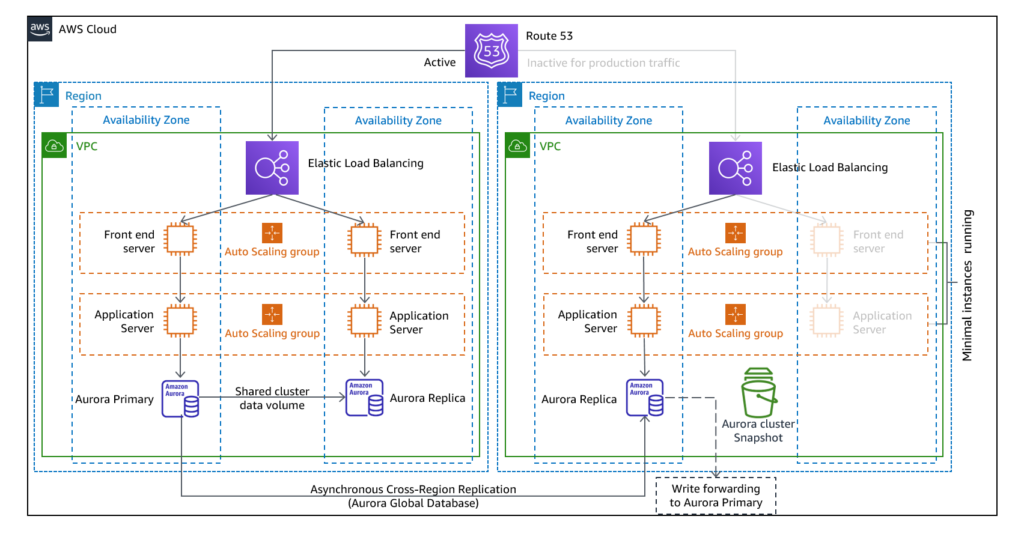
- Warm Standby: This takes the Pilot-light approach to the next level by reducing recovery time to almost zero. It maintains a completely functional version of your workload always running in the Disaster Recovery region, but this is scaled down. All the business-critical systems are always ON and completely duplicated but in a scaled-down mode. At the time of recovery, these systems are scaled up and ready to handle the load. Here, the recovery is fast but hosting costs are higher for large backup instances. Pilot Light cannot process requests without additional actions, whereas Warm Standby just requires you to scale up, as everything else is already deployed.
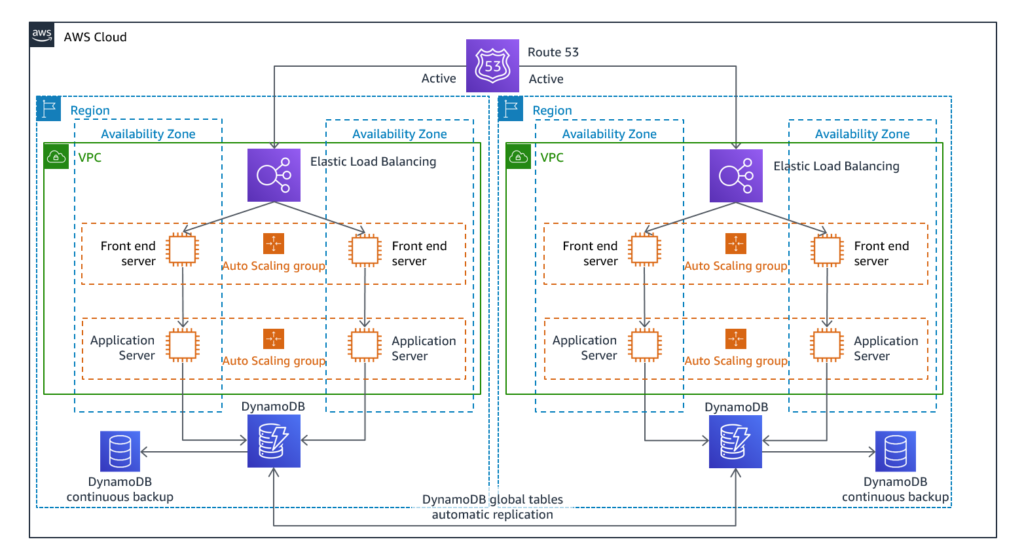
- Multisite or active-active: Here the workload is deployed to multiple AWS Regions, and it actively serves traffic from these regions. An identical solution to your on-site infrastructure runs on AWS. In case of disaster entire traffic is routed to AWS and then the AWS infrastructure can be scaled accordingly. This is the most costly and complex approach but it brings down the recovery time to near zero.
Tech Vedika Case Study
Tech Vedika implemented Backup & Restore for multiple enterprise clients. For a large enterprise customer in the USA in Media & Entertainment domain, we used Automated Backup to S3 for RDS MySQL. The frequency of backup was configured to one time per night. The Retention period was configured to 7 days. For EC2 backup we configured periodic Snapshots. S3 buckets were archived to Glacier.
Conclusion
Companies save at least 50% of the cost by deploying AWS Backup and Disaster Recovery Solution as compared to maintaining one of their own. These approaches offer varied costs, scalability, and durability to meet compliance requirements. Enterprises deploy a mix of these strategies to achieve their business goals. RTO and RPO should be decided carefully to ensure seamless continuity of the business.
Image Source: AWS Well-Architected Framework Whitepaper